
最近在爬一个网站。有5万条左右的数据,为了友好期间,把间隔时间设置为5s,这个算下来总共要花好几天的时间。中间由于网络原因中断过几次,每次都得从头开始爬。所以就想着用断点续爬。正好scrapyd-redis 满足这个需求。
1 安转redis
wget http://download.redis.io/releases/redis-6.0.6.tar.gz tar xzf redis-6.0.6.tar.gz cd redis-6.0.6 src/redis-server
2 安装scrapyd-redis
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy-redis
3 修改settings.py 文件
ROBOTSTXT_OBEY = False // 设置为false // 增加几行 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #定义一个去重的类,用来将url去重 SCHEDULER = "scrapy_redis.scheduler.Scheduler" #指定队列 SCHEDULER_PERSIST = True #将程序持久化保存 REDIS_URL = "redis://192.168.0.103:6379" # reids 链接信息
4 重新启动爬虫
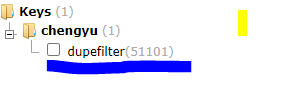
如果发现redis 里面多了dupefilter 这一例表示scrapyd-redis 起作用了。